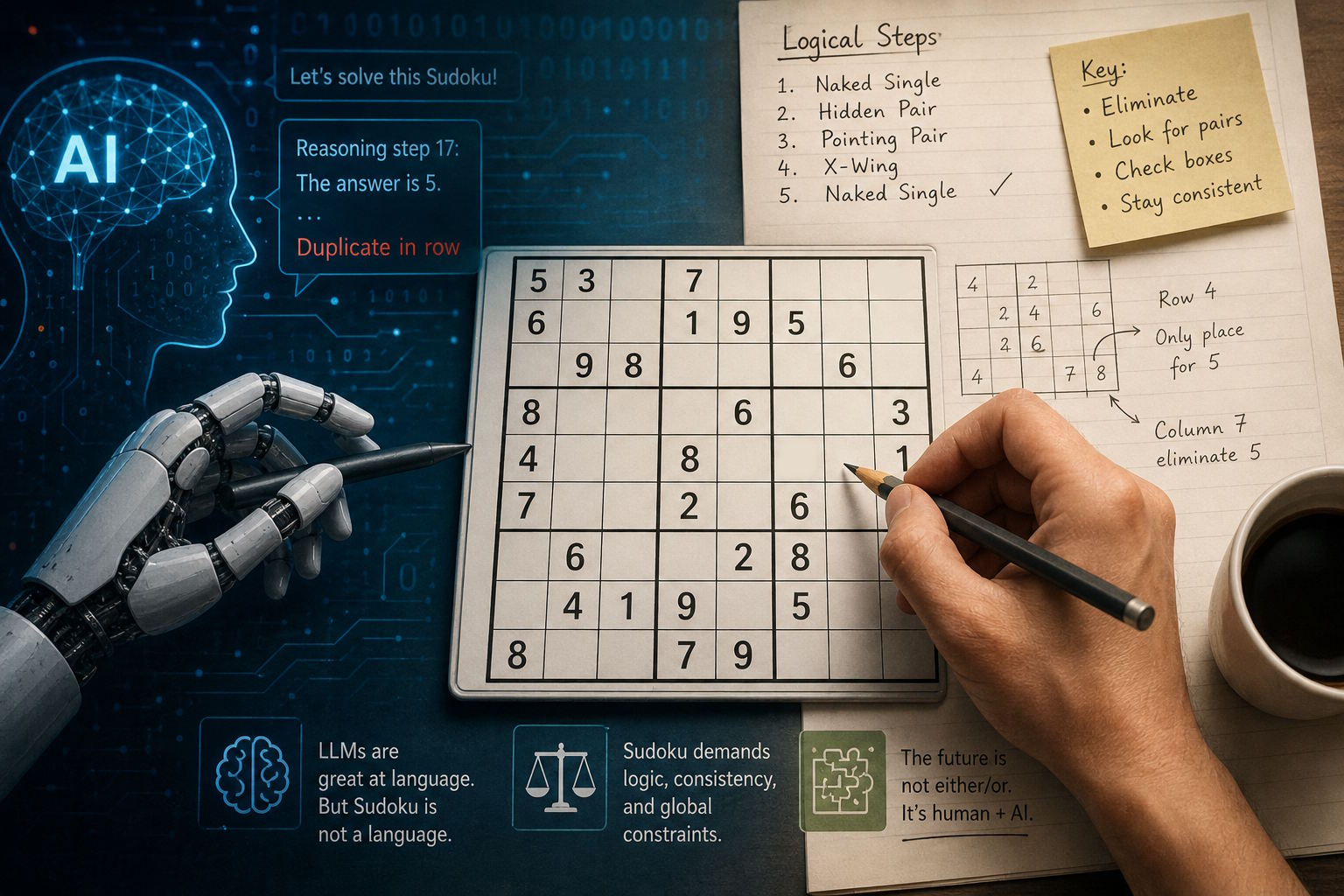
Sudoku is often dismissed as a pastime – a commuter’s distraction or a quiet ritual over morning coffee. But beneath its minimalist design lies something more fundamental, a pure test of reasoning.
No external knowledge is required. No ambiguity exists. Every valid solution emerges from a strict set of constraints. That makes Sudoku not just a puzzle, but a near-perfect laboratory for studying intelligence – human or artificial.
And in the age of large language models (LLMs), that laboratory is revealing something uncomfortable.
A clean test that AI keeps failing
Modern LLMs, such as ChatGPT and its peers, have demonstrated remarkable fluency. They write essays, generate code, and mimic structured reasoning. But when asked to solve Sudoku, their performance drops sharply.
This is not anecdotal. Recent academic work confirms it.
A study presented in Findings of the Association for Computational Linguistics (ACL 2025) found that while some models could occasionally reach correct solutions, none were able to provide explanations that reflected genuine logical reasoning, as detailed in the paper available via the ACL Anthology.
Similarly, researchers at the University of Colorado Boulder reported that LLMs can sometimes solve easier puzzles, but struggle with harder ones and frequently generate misleading explanations of their reasoning, according to their published findings
Benchmarks designed specifically to evaluate multi-step reasoning, such as Sudoku-Bench, reinforce the same pattern—showing that leading models solve only a small fraction of complex puzzles, as summarized in recent benchmark overviews.
For a task that many humans treat as a warm-up exercise, this gap is hard to ignore.
The real issue: constraint satisfaction vs. language prediction
The problem is not Sudoku. It is architecture.
Sudoku belongs to a class of problems known as constraint satisfaction problems (CSPs), where a solution must satisfy a set of global rules simultaneously. This class includes scheduling, planning, and many industrial optimization tasks.
Research in this area has long relied on structured methods such as backtracking and search algorithms, or hybrid neural approaches that evaluate entire solution states, as explored in work on neural combinatorial optimization.
LLMs, however, operate differently.
They generate text token by token, predicting what is likely to come next. This works well for language, but poorly for problems where:
- constraints must be globally consistent
- earlier decisions may need revision
- correctness is binary, not probabilistic
Recent work presented at venues like International Conference on Learning Representations shows that even when transformer-based models are adapted for structured reasoning, they require additional mechanisms—such as recurrence or constraint-aware architectures—to perform reliably (https://openreview.net/forum?id=udNhDCr2KQe).
In other words, Sudoku exposes a fundamental mismatch:
LLMs simulate reasoning. They do not enforce it.
Attempts to fix the gap
Researchers are actively working to bridge this gap.
One direction involves augmenting LLMs with structured reasoning strategies. Techniques like Tree-of-Thought encourage models to explore multiple reasoning paths and backtrack when necessary, as described in the original paper.
Another approach combines neural networks with symbolic constraint solvers. For example, recent work on perception-based Sudoku solving integrates neural perception with constraint satisfaction systems, significantly improving reliability.
There is also growing interest in alternative architectures—such as energy-based models—that evaluate solutions more holistically rather than sequentially.
The direction is clear:
Pure language models are not enough.
A deeper implication: reasoning is not fluency
Sudoku highlights a broader issue in modern AI discourse.
Fluency—the ability to produce coherent text—is often mistaken for reasoning. But the two are fundamentally different.
Benchmarks like Sudoku-Bench, introduced to test creative and structured reasoning, exist precisely because many existing evaluations reward pattern recognition rather than true deduction.
Sudoku, by contrast, demands:
- global consistency
- step-by-step deduction
- error correction
These are exactly the areas where LLMs remain fragile.
And yet, this is not a failure story
It would be easy to frame this as a limitation of AI. But that misses the more interesting point.
LLMs may not be reliable solvers—but they are powerful communicators.
Research into natural-language explanations of puzzle solving shows that models can help translate complex reasoning into accessible explanations for users, even if their internal reasoning is imperfect.
In practice, this suggests a different role:
- Not as the engine that solves Sudoku
- But as the system that explains it
In hybrid systems, this division is already emerging:
- Algorithms ensure correctness
- LLMs provide explanations, hints, and teaching
For consumer-facing products, that distinction matters.
Sudoku as a mirror
Sudoku is not important because of the puzzle itself. It matters because of what it reveals.
It shows that:
- Intelligence is not just pattern generation
- Reasoning requires structure, not just probability
- Current AI systems excel at communication—but still struggle with consistency
In a field often driven by hype, that clarity is valuable.
Leave a Reply